
Cursor를 만드는 Anysphere가 2026년 3월 19일 세 번째 자체 코딩 모델인 Composer 2를 공개했다. 2025년 10월 첫 번째 Composer 출시 이후 약 5개월 만에 나온 이 모델은, 이전 세대 대비 벤치마크 점수를 최대 61% 이상 끌어올리면서도 입력 토큰 100만 개당 0.50달러라는 가격표를 달았다. 범용 대형 언어 모델(LLM)이 아니라 코딩이라는 단일 도메인에 자원을 집중한 결과다.
이 모델이 주목받는 이유는 크게 두 가지다. 하나는 '지속적 사전학습(continued pretraining)'이라는 기법을 처음 적용해 강화학습의 기반 자체를 강화했다는 점이고, 다른 하나는 자기요약(self-summarization)이라는 독자적 기법으로 수백 턴에 걸치는 장기 코딩 작업을 한 번에 처리할 수 있게 만들었다는 점이다.
이 문서에서는 Composer 2의 벤치마크 성적과 가격 구조, 핵심 기술인 자기요약 강화학습, 그리고 범용 모델 대비 도메인 특화 모델이 갖는 경쟁력을 데이터 중심으로 정리한다.
- 커서 공식 홈페이지 블로그 : https://cursor.com/ko/blog/composer-2
1. Composer 시리즈의 진화 경로
Cursor의 모회사 Anysphere는 2022년 설립 이후 타사 모델(Claude, GPT 등)을 통합해 코딩 에디터를 운영해왔다. 자체 모델 개발은 2025년 하반기부터 본격화되었으며, 약 5개월 사이에 세 차례 모델을 연이어 출시했다.
1.1 Composer 1 – 첫 자체 모델
- 2025년 10월 29일 Cursor 2.0과 함께 공개되었다. 혼합 전문가(Mixture-of-Experts, MoE) 아키텍처를 채택했으며, MXFP8 최적화를 통한 저정밀도 추론으로 유사 성능 모델 대비 4배 빠른 응답 속도를 내세웠다.
- 코딩 특화 강화학습으로 훈련했지만, 사전학습 베이스 모델 자체를 코딩에 맞춰 재훈련하지는 않았다. CursorBench 점수 38.0, Terminal-Bench 2.0 점수 40.0으로, 당시 Claude Haiku 4.5나 Gemini Flash 2.5 급으로 평가받았다.
1.2 Composer 1.5 – 강화학습 20배 확장
- 2026년 2월 9일 출시되었다. 같은 사전학습 모델 위에서 강화학습 연산량을 20배 늘렸으며, 사후학습(post-training)에 투입된 연산이 사전학습 연산을 넘어선 것으로 알려졌다.
- 사고 토큰(thinking tokens)을 사용하는 '씽킹 모델'로 전환했다. 쉬운 문제에는 최소한의 사고로 빠르게 응답하고, 어려운 문제에는 충분히 사고한 뒤 답을 내는 적응형 사고 방식을 적용했다.
- 자기요약 기능이 처음 도입되었다. CursorBench 44.2, Terminal-Bench 2.0 47.9로 Composer 1 대비 약 20% 향상을 보였으며, Cursor 공식 블로그는 Sonnet 4.5 이상, Opus 4.5 미만의 위치로 평가했다.
1.3 Composer 2 – 지속적 사전학습 도입
- 2026년 3월 19일 공개. 이전 버전과의 가장 큰 차이는 지속적 사전학습을 최초로 적용했다는 점이다. 이는 기존 베이스 모델을 코딩 데이터로 추가 사전학습해 강화학습의 출발선 자체를 높이는 접근이다.
- CursorBench 61.3, Terminal-Bench 2.0 61.7, SWE-bench Multilingual 73.7을 기록했다.
핵심 포인트: Composer 시리즈는 5개월 동안 CursorBench 기준 38.0에서 61.3으로, Terminal-Bench 2.0 기준 40.0에서 61.7로 도약했다. 각 세대마다 사전학습 기반 강화, 사고 토큰 도입, 자기요약 훈련이라는 명확한 기술 업그레이드가 있었다.
2. 벤치마크 성적과 경쟁 모델 비교
Composer 2의 성적을 다른 모델과 비교하려면, 벤치마크마다 사용하는 에이전트 하네스가 다르다는 점을 먼저 이해해야 한다. Terminal-Bench 2.0에서 Anthropic 모델은 Claude Code 하네스를, OpenAI 모델은 Simple Codex 하네스를 사용한다. Cursor는 공식 Harbor 평가 프레임워크를 사용했으며, 모델-에이전트 쌍별로 5회 반복 실행 후 평균값을 보고했다.
2.1 Composer 내부 세대 간 비교
| 모델 | CursorBench | Terminal-Bench 2.0 | SWE-bench Multilingual |
|---|---|---|---|
| Composer 2 | 61.3 | 61.7 | 73.7 |
| Composer 1.5 | 44.2 | 47.9 | 65.9 |
| Composer 1 | 38.0 | 40.0 | 56.9 |
Composer 2는 전작 대비 CursorBench에서 38.7%, Terminal-Bench 2.0에서 28.8%, SWE-bench Multilingual에서 11.8% 향상을 보인다.
2.2 Terminal-Bench 2.0 외부 모델과의 위치
Terminal-Bench 2.0 공식 리더보드(2026년 3월 기준)에서 상위권 점수는 다음과 같다.
| 순위 대역 | 모델 (에이전트 포함) | 점수 |
|---|---|---|
| 최상위 | GPT-5.3 Codex + Simple Codex | 약 77% |
| 상위 | Claude Opus 4.6 + Claude Code | 약 69-75% |
| 중상위 | GPT-5.2 Codex, Gemini 3.1 Pro | 약 64-68% |
| Composer 2 위치 | Composer 2 + Harbor 하네스 | 61.7% |
Composer 2의 61.7%는 리더보드 전체에서 최상위는 아니지만, 에이전트 하네스 차이를 감안해야 한다. Claude Opus 4.6은 Claude Code라는 전용 에이전트와 함께 측정한 점수이고, Composer 2는 범용 Harbor 프레임워크에서 기본 설정으로 돌린 결과다. Cursor 측은 자사 에디터 내부에서의 실제 개발자 경험이 벤치마크 수치보다 더 유의미하다는 입장을 CursorBench 소개 글에서 밝히고 있다.
2.3 CursorBench의 차별점
Cursor는 2026년 3월 11일 공개한 CursorBench 관련 블로그에서 공개 벤치마크의 한계를 세 가지로 지적했다. 첫째, SWE-bench 계열은 버그 수정 중심이라 실제 개발 작업과 괴리가 있다. 둘째, 좁은 정답 범위를 가정해 대안적 정답을 불이익 처리한다. 셋째, 공개 저장소에서 추출한 태스크가 모델 학습 데이터에 오염되어 점수가 부풀려진다. OpenAI도 이 문제를 인정해 SWE-bench Verified 결과 보고를 중단한 바 있다.
CursorBench는 Cursor의 내부 코드베이스와 Cursor Blame 기능을 활용해 실제 개발자의 에이전트 요청-커밋 쌍에서 태스크를 추출한다. 태스크 설명이 의도적으로 짧고 모호하게 유지되며, 이는 개발자가 에이전트에 지시하는 실제 방식에 더 가깝다.
핵심 포인트: 벤치마크 점수를 단순 비교할 때는 에이전트 하네스, 태스크 유형, 데이터 오염 여부를 반드시 함께 확인해야 한다. Composer 2의 Terminal-Bench 61.7%는 Harbor 기본 설정 기준이며, 같은 벤치마크에서 Claude Opus 4.6이 Claude Code와 결합해 69-75% 대역을 기록한다.
3. 자기요약 강화학습 – Composer 2의 핵심 기술
Composer 2의 성능 도약을 이해하려면 자기요약(self-summarization)이라는 훈련 기법을 파악해야 한다. 이 기법은 Composer 1.5에서 처음 도입되었고, Composer 2에서 지속적 사전학습과 결합해 더 강화되었다.
3.1 컨텍스트 한계 문제
- 복잡한 코딩 작업은 수백 번의 동작이 필요하다. 파일 탐색, 코드 수정, 터미널 명령, 테스트 실행이 반복되면서 에이전트의 컨텍스트(대화 기록)는 빠르게 늘어난다.
- 모든 LLM에는 최대 컨텍스트 길이가 있다. 이 한계에 도달하면 기존 하네스는 두 가지 방식 중 하나로 대응한다. 프롬프트 기반 요약(별도 모델이 맥락을 요약)이거나 슬라이딩 윈도우(오래된 맥락을 잘라냄)다.
- 두 방식 모두 핵심 정보를 잃을 위험이 있다. Cursor의 실험에 따르면, 이 정보 손실이 장기 작업의 정확도를 크게 떨어뜨린다.
3.2 자기요약의 작동 방식
- Composer가 프롬프트에서 생성을 시작하고, 고정된 토큰 길이 트리거에 도달하면 일시 정지한다.
- 모델이 현재 컨텍스트를 요약하라는 합성 쿼리를 받는다.
- 모델은 스크래치 공간에서 어떤 정보가 가장 중요한지 사고한 뒤, 압축된 컨텍스트를 생성한다.
- 이 압축 컨텍스트(요약 + 대화 상태 + 남은 작업 등)를 기반으로 다시 1단계로 돌아간다.
이 과정이 기존 프롬프트 기반 요약과 결정적으로 다른 점은 훈련 루프 안에 요약이 포함된다는 것이다. 강화학습 롤아웃 시 생성-요약-생성 체인 전체에 최종 보상이 적용되므로, 좋은 요약은 강화되고 나쁜 요약은 약화된다.
3.3 수치로 본 효과
- 압축 오류 50% 감소: 정교하게 설계한 프롬프트 기반 요약(수천 토큰 분량의 지시문, 12개 이상의 보존 항목을 명시한 기존 방식) 대비, 자기요약은 압축 오류를 절반으로 줄였다.
- 토큰 효율 5배: 프롬프트 기반 요약의 출력이 평균 5,000토큰 이상인 반면, 자기요약의 출력은 평균 약 1,000토큰이다. 모델이 맥락에 따라 보존할 정보를 스스로 판단하기 때문이다.
- KV 캐시 재사용: 자기요약은 이전 토큰의 중간 연산 결과를 저장한 KV 캐시를 재활용할 수 있어, 추론 비용이 추가로 절감된다.
3.4 실제 사례 – DOOM for MIPS
Cursor는 Terminal-Bench 2.0의 make-doom-for-mips 문제를 사례로 제시했다. 이 문제는 DOOM 소스코드를 MIPS 아키텍처에서 실행하도록 크로스컴파일하고, JavaScript VM 위에서 동작하게 만드는 작업이다. 여러 프런티어 모델이 공식 점수에서 해결하지 못한 이 문제를, Composer의 연구 체크포인트가 170턴에 걸쳐 해결했다. 작업 과정에서 10만 토큰 이상의 맥락이 약 1,000토큰의 구조화된 요약으로 압축되었다.
핵심 포인트: 자기요약은 단순한 맥락 관리 기법이 아니라, 강화학습 보상 신호가 직접 적용되는 훈련 대상이다. 덕분에 프롬프트 요약 대비 오류 50% 감소, 토큰 5분의 1 사용이라는 효율을 달성했다.
4. 가격 구조와 비용 효율
Composer 2는 두 가지 요금제로 제공된다.
4.1 표준 버전과 Fast 버전 비교
| 항목 | 표준(Standard) | 빠른(Fast) |
|---|---|---|
| 입력 토큰 100만 개 | $0.50 | $1.50 |
| 출력 토큰 100만 개 | $2.50 | $7.50 |
| 지능 수준 | 동일 | 동일 |
| 용도 | 비용 최적화 | 대화형 세션 기본값 |
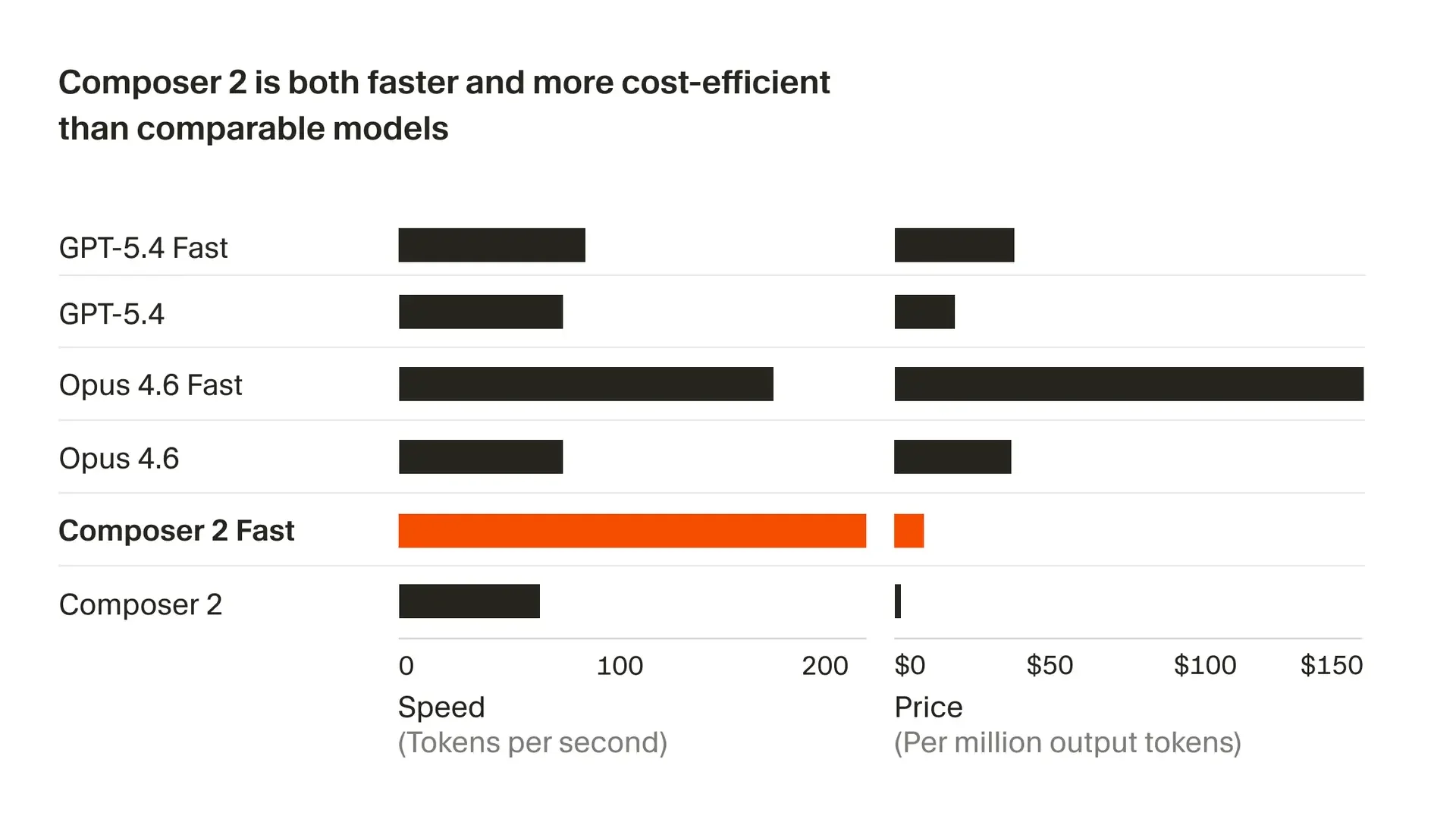
Fast 버전이 Cursor 제품 내 기본 옵션으로 설정된다. Cursor 측은 이 Fast 버전도 유사 속도의 타사 모델보다 비용이 낮다고 밝혔다.
4.2 주요 모델 출력 토큰 가격 비교
Cursor가 2026년 3월 18일 트래픽 스냅샷을 기준으로 발표한 비교에서, Anthropic 토큰은 약 15% 더 작기 때문에 토큰당 속도(TPS)와 가격이 정규화되었다. 아래는 각 모델의 공식 출력 토큰 가격을 개략적으로 비교한 것이다.
| 모델 | 출력 토큰 100만 개당 가격 (공식) | 비고 |
|---|---|---|
| Composer 2 표준 | $2.50 | Cursor 자체 모델 |
| Composer 2 Fast | $7.50 | 기본 옵션 |
| Claude Opus 4.5 | $75.00 | Anthropic 공식(토큰 크기 차이 미반영) |
| Claude Sonnet 4.5 | $15.00 | Anthropic 공식 |
| GPT-5 | $30.00-60.00 대역 | 버전·설정에 따라 상이 |
표준 버전 기준으로 Composer 2의 출력 토큰 가격은 Claude Sonnet 4.5의 약 6분의 1, Opus 4.5의 약 30분의 1 수준이다. 물론 Composer 2는 코딩 전용이고 Claude나 GPT는 범용이므로 직접 비교에는 한계가 있다.
4.3 개인 플랜과 팀 플랜 차이
개인(Pro) 플랜에서는 Composer 사용량이 별도의 Composer 전용 사용량 풀에 포함되어 넉넉한 기본 제공량이 주어진다. 팀·엔터프라이즈 플랜에서는 위 API 가격이 직접 과금된다.
핵심 포인트: Composer 2의 가격 경쟁력은 코딩에만 집중한 도메인 특화 설계에서 나온다. 범용 모델이 감당해야 하는 다국어·다영역 데이터 학습 비용이 빠지면서, 동일 성능 대비 훨씬 낮은 추론 비용을 실현했다.
5. 도메인 특화 모델 vs 범용 모델 – 산업 트렌드
Composer 2의 등장은 AI 모델 시장에서 나타나고 있는 구조적 변화를 잘 보여준다.
5.1 범용 모델의 딜레마
- OpenAI, Anthropic, Google 등은 하나의 모델로 코딩·글쓰기·분석·대화 등 모든 영역을 커버하는 전략을 취한다. 이 접근은 학습 데이터 규모와 연산 비용이 기하급수적으로 증가한다.
- SWE-bench Verified에서 프런티어 모델 간 점수 차이가 좁혀지면서, 범용 모델 간의 코딩 성능 차별화가 어려워지고 있다. OpenAI가 SWE-bench Verified 결과 보고를 중단한 배경에는 데이터 오염 문제도 있지만, 벤치마크 포화 현상도 영향을 미쳤다.
5.2 도메인 특화의 이점
- Cursor의 Composer는 코딩 데이터에만 집중해 사전학습과 강화학습을 수행한다. 범용 지식을 버리는 대신 코딩 도구 사용, 파일 편집, 터미널 조작에 최적화된 행동 패턴을 학습한다.
- MoE 아키텍처와 결합하면, 활성화되는 파라미터 수를 줄이면서도 코딩 전용 전문가 네트워크가 높은 품질을 유지할 수 있다. 이것이 낮은 추론 비용의 기술적 배경이다.
- PromptLayer 블로그의 분석에 따르면, Composer의 성공은 좁은 범위에 집중한 특화 LLM이 자신의 도메인에서 범용 모델을 능가할 수 있음을 실증한 사례로 평가된다.
5.3 경쟁 구도의 변화
- Anysphere는 2025년 11월 Series D에서 23억 달러를 조달하며 기업가치 293억 달러를 달성했고, 연간 반복 수익(ARR) 10억 달러를 넘겼다. 2026년 3월에는 600억 달러 밸류에이션으로 추가 자금 조달을 검토 중이라는 보도도 나왔다.
- Augment Code의 Auggie, Claude Code, GitHub Copilot 등 경쟁 제품도 코딩 특화 에이전트를 강화하고 있어, 이 시장은 빠르게 성장 중이다.
- Cursor가 자체 모델을 갖게 됨으로써, 타사 모델 의존도를 낮추고 가격·속도·품질을 동시에 통제할 수 있는 수직 통합 체계를 확보한 셈이다.
6. Composer 2의 기술 구조 요약
기술 구조를 한눈에 정리하면 아래와 같다.
| 구성 요소 | 내용 |
|---|---|
| 아키텍처 | 혼합 전문가(MoE) 기반, 장문 컨텍스트 생성·이해 지원 |
| 추론 최적화 | MXFP8 저정밀도 추론 |
| 사전학습 | 최초의 지속적 사전학습 적용(코딩 데이터 집중) |
| 사후학습 | 대규모 강화학습, 자기요약 훈련 통합 |
| 에이전트 도구 | 시맨틱 검색, 파일 편집, 터미널 명령, 코드 실행 등 Cursor 전체 도구 접근 |
| 컨텍스트 관리 | 자기요약으로 장기 작업 시 정보 보존, 80K·40K 트리거 설정 가능 |
| 사고 모델 | 적응형 사고 토큰 사용(쉬운 문제는 짧게, 어려운 문제는 길게) |
7. 마무리
위에서 살펴본 Cursor Composer 2의 핵심 내용을 정리하면 다음과 같습니다.
핵심 요약:
- Composer 2는 지속적 사전학습을 최초 적용해 강화학습의 기반을 근본적으로 강화한 코딩 특화 모델이다
- CursorBench 61.3, Terminal-Bench 2.0 61.7, SWE-bench Multilingual 73.7로 전 세대 대비 전 벤치마크에서 큰 폭의 성능 향상을 기록했다
- 자기요약 강화학습으로 프롬프트 기반 요약 대비 압축 오류 50% 감소, 토큰 사용량 5분의 1을 달성했다
- 표준 버전 기준 입력 $0.50/M, 출력 $2.50/M으로 프런티어 모델 대비 파격적인 가격을 제시한다
- Fast 버전($1.50/$7.50)이 제품 기본값으로, 유사 속도의 타사 모델보다 저렴하다
- 범용 모델이 아닌 코딩 특화 수직 통합 전략이 가격·속도·품질의 동시 최적화를 가능하게 했다
코딩 에이전트를 도입하거나 전환을 고려하는 상황이라면, Composer 2의 실질적 판단 기준은 벤치마크 점수 자체가 아니라 자신의 워크플로에서 얼마나 빠르고 정확하게 작업을 완료하는지, 그리고 그에 대한 비용이 합리적인지 여부다. Cursor Pro 플랜에서 별도 비용 없이 기본 포함되는 사용량으로 직접 테스트해보는 것이 가장 확실한 검증 방법이다.